
Dieser Beitrag ist die dritte Fortsetzung meiner Serie über das Vier-Ebenen-Modell, in dem es um die Datenhaltungsstrategien für IIoT-Anwendungen geht. Nach der Datenerfassungs- und der Datentransferebene entscheidet sich hier, ob deine wertvollen Produktionsdaten langfristig nutzbar bleiben oder im digitalen Chaos versinken. Diese Reise führt uns in das Herzstück der industriellen Digitalisierung: Die systematische Organisation eine deiner wertvollsten Ressource – der Daten. Es geht sowohl um Speicherkonzepte mit Hot-, Warm- und Cold-Storage, als auch die Auswahl der passenden Datenbanktypen und ausgereifte Betriebsführungskonzepten. Die richtige Datenhaltungsstrategie bildet das Fundament für die spätere Datenanalyse und verhindert, dass deine Smart Factory an ihrer eigenen Datenmenge erstickt.
Speicherorte für Daten im Detail
Datenhaltungsstrategien in IIoT-Anwendungen meint vereinfacht gesagt die Speicherung von Daten, wobei die allererste Frage häufig „Wo?“ ist. Deswegen beginnen wir mit den Speicherorten der Daten.
Der zentrale Übergabepunkt für die Datentransferebene zur Datenhaltungsebene ist der Speicherort der Daten, quasi die Adresse zum Versand der Daten. Hier gibt es grundsätzlich mehrere Optionen, welche jeweils bestimmte Anwendungsfalle ausgelegt sind:
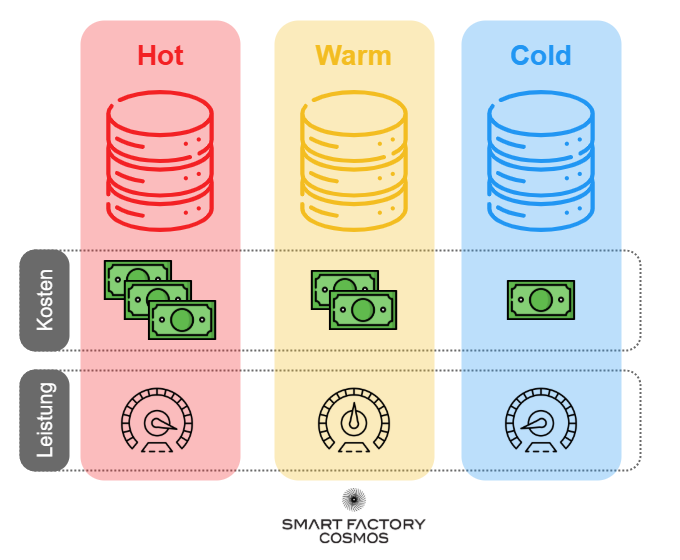
- Hot-Storage bedeutet, dass die Daten sehr nahe an der Erfassungs- und Verarbeitungsstelle gehalten werden, z.B. direkt im Feld. Die Schreib- und Lesezeiten sind hier sehr kurz, was vor allem für Echtzeit-Anwendungen und Prozesssteuerung wichtig ist.
- Ein Warm-Storage ist nicht direkt im Feld, allerdings auch nicht in einem weit entfernten Datencenter. Das kann z.B. eine SQL-Datenbank auf einem lokalen Server sein. Es ist ein optimales Setup für mittlere Latenzanforderungen für operative Analysen und kurzfristige Historisierung.
- Cold-Storage spielt sich in einem entfernten Datencenter ab, meistens ein Cloudspeicher wie beispielsweise Amazons AWS oder Microsofts Azure . Hier kann eine langfristige Archivierung erfolgen und durch umfangreiche Cloud-Rechenleistungen Big-Data-Analysen effizient durchgeführt werden.
Orientierungshilfe zum Speicherort
Damit du den Speicherort in der Datenhaltungsstrategien für deine IIoT-Anwendungen besser beurteilen kannst, habe ich folgende Aspekte zu einer Orientierungshilfe zusammengefasst:
| Aspekt | Beschreibung |
|---|---|
| Latenz | Die Zugriffsgeschwindigkeit bestimmt maßgeblich die Echtzeit-Fähigkeit von Anwendungen. Hot-Storage bietet minimale Latenz für zeitkritische Prozessdaten. |
| Kosten | Ein entscheidender Faktor sind natürlich die Kosten. Hot-Storage ist teurer als Cold-Storage. Die Kostenstruktur steht meist in direktem Zusammenhang mit der Zugriffsgeschwindigkeit. |
| Zugriffsfrequenz | Wie oft auf die Daten zugegriffen wird, ist neben der Latenz ein Hauptkriterium für die Speicherortwahl. |
| Datenvolumen | Große Datenmengen werden oft in kostengünstigeren Cold-Storage verschoben, während kleinere, häufig benötigte Datensätze im Hot-Storage verbleiben. |
| Lebenszyklus der Daten | Damit ist der zeitliche Wertverlauf von Daten gemeint. Frische Produktionsdaten sind oft wertvoller als historische und rechtfertigen schnelleren Zugriff. |
| Compliance und Aufbewahrungspflichten | Rechtliche Anforderungen können bestimmte Speicherorte oder Aufbewahrungszeiten vorschreiben. |
| Verfügbarkeitsanforderungen | Wie schnell Daten nach einem Systemausfall wieder verfügbar sein müssen. |
Multi-Tier-Architekturen
Dieser Architekturansatz kombiniert verschiedene Speicherebenen für eine optimale Balance zwischen Leistung, Kosten und Zugänglichkeit. In diesem hierarchischen Ansatz werden Daten basierend auf ihrem Wert, Alter und ihrer Nutzungshäufigkeit automatisch zwischen den Speicherebenen verschoben. Typischerweise durchlaufen Daten einen Lebenszyklus vom Hot-Storage über Warm-Storage hin zum Cold-Storage. In der Enterprise-IT wird dieses Konzept oft als „Tiered Storage“ mit numerischen Bezeichnungen (Tier-0 bis Tier-3) beschrieben, wobei Tier-0/1 dem Hot-Storage, Tier-2 dem Warm-Storage und Tier-3 dem Cold-Storage entspricht.
Unabhängig von der Terminologie bleibt das Grundprinzip gleich: Je älter und weniger relevant die Daten werden, desto kostengünstiger und langsamer wird ihr Speicherort. Der Hauptvorteil liegt in der Kosteneffizienz bei gleichzeitiger Sicherstellung, dass Daten mit der jeweils angemessenen Geschwindigkeit verfügbar sind. Zum Tiered-Storage kann ich dir diesen Artikel von ComputerWeekly empfehlen:
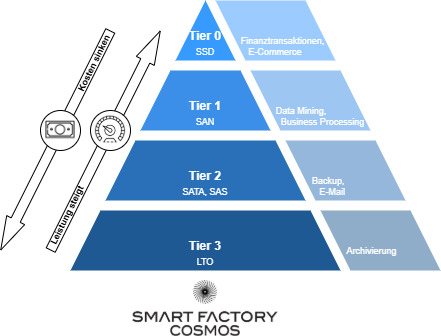
In einer Datenhaltungsstrategien für IIoT-Anwendungen könnte eine Multi-Tier-Architektur beispielsweise so aussehen:
- Aktuelle Produktionsdaten verbleiben im Edge-basierten Hot-Storage für Echtzeit-Prozessoptimierungen.
- Nach einigen Stunden werden die Daten in einen Warm-Storage auf lokalen Servern verschoben für operative Analysen.
- Nach einigen Tagen erfolgt die Verlagerung in Cloud-basierte Cold-Storage-Systeme für langfristige Archivierung und umfangreiche historische Analysen.
Datenbanktypen und ihre optimalen Einsatzgebiete
Nachdem wir in der Datenhaltungsstrategien für eine IIoT-Anwendungen das „Wo“ festgelegt haben, geht es als nächstes um das „Wie“. Die Datenbanktypen sind die Art der Datenspeicherung und hängen maßgeblich davon ab, wie die auf der Datenerzeugungsebene generierten Daten formatiert sind. Auch hier gibt es entsprechend mehrere Typen, die erneut vom Anwendungsfall abhängen. Man kann sie grundsätzlich in relationale (SQL) und nicht-relationale Datenbanktypen (NoSQL) unterteilen.

Ich betrachte die Haltung von Rohdaten (wie z.B. Messwerte, Sensordaten, Prozessdaten). Die Speicherung von Dateien (Protokolle, Bilder, Konfigurationsdateien) erfordert andere Ansätze wie File-Storage-Systeme oder Object Storage.
Relationale Datenbanken
Sie werden auch SQL genannt und sind klassische Datenbanken in der IT. Im IIoT-Kontext können sie für strukturierte Betriebs- und Stammdaten, Konfigurationen und Beziehungen zwischen Komponenten eingesetzt werden. Bekannte Beispiele sind MySQL oder PostgreSQL.
Zeitreihendatenbanken
Oft als Data Historian, oder einfach nur Historian, bezeichnet sind sie eine Art von Datenbank, die für die Erfassung und Speicherung von Zeitreihendaten aus verschiedenen Quellen rund um eine Anlage wie z.B. Sensordaten und Messwerte mit Zeitstempeln optimiert sind. Beispiele sind InfluxDB oder TimescaleDB.
Während relationale Datenbanken darauf ausgelegt sind, Daten in Zeilen und Spalten zu strukturieren, richtet eine Zeitreihendatenbank oder -infrastruktur Sensordaten nach der Zeit als primärem Index aus.
Quelle: Dataparc
NoSQL-Datenbanken
Im Gegensatz zu den vorherigen Datenbanken sind dies solche, die Daten ohne feste Tabellenstruktur enthalten können. Sie haben keine Relationen untereinander und dadurch eine hohe Flexibilität im Sinne der horizontalen und vertikalen Skalierbarkeit:
- Dokumentenorientiert für halbstrukturierte Daten und flexible Schemas (z.B. MongoDB)
- Key-Value-Stores: Für schnelle Zugriffe und einfache Strukturen (z.B. Redis)
- Wide-Column-Stores: Für massiv skalierbare Datenmengen (z.B. Cassandra)
- Graph-Datenbanken: Für komplexe Beziehungen zwischen Geräten und Systemen (z.B. Neo4j)
Diesen Artikel von IBM kann ich für eine nähere Erläuterung empfehlen.
Edge-Datenbanken
Sie werden direkt auf Edge-Geräten oder Gateways in der Nähe der Datenquelle eingesetzt. Vertreter wie SQLite und RocksDB arbeiten ressourcenschonend und ermöglichen lokale Datenspeicherung und -verarbeitung ohne Übertragungsverzögerungen. Sie reduzieren Latenz, ermöglichen Echtzeitreaktionen und funktionieren auch bei instabilen Netzwerkverbindungen durch lokale Zwischenspeicherung.
In Smart Factories kannst du Edge-Datenbanken gezielt für drei Hauptanwendungen einsetzen: zeitkritische Prozesssteuerungen, lokale Datenanalysen und die effektive Vorfilterung von Daten vor der Weiterleitung an zentrale Speichersysteme.
Betriebsführungskonzepte für IIoT-Anwendungen
Während sich viele auf die technischen Details der Datenbankauswahl und Implementierung konzentrieren, geraten Themen wie Datenmanagement-Prozesse, Data Governance, Backup-Strategien oder Lebenszyklus-Management leicht in den Hintergrund. Für mich sind diese Aspekte jedoch genau so Bestandteil einer Datenhaltungsstrategien für IIoT-Anwendungen. Schließlich entscheiden diese Punkte oft darüber, ob deine Datenhaltungslösung langfristig zuverlässig, sicher und wartbar bleibt. Ohne klare Prozesse für Datenverwaltung können selbst technisch perfekte Lösungen im Alltag scheitern.
Datenmanagement und Data Governance
Datenmanagement umfasst das „sichere, effiziente und kostengünstige Erfassen, Speichern und Verwerten von Daten“. Es unterstützt Organisationen dabei, ihre Datennutzung im Einklang mit Richtlinien zu optimieren, um fundierte Entscheidungen zu treffen und den Unternehmenswert zu steigern. In einer Zeit, in der immaterielle Ressourcen zunehmend wertschöpfend sind, wird eine durchdachte Datenmanagementstrategie zum entscheidenden Erfolgsfaktor. (Quelle: Oracle)
Data Governance bezeichnet den strategischen Rahmen zur Verwaltung von Unternehmensdaten mit Fokus auf deren Qualität, Sicherheit und Verfügbarkeit. Damit schaffst du die Grundlage für Datenintegrität und -schutz durch die Entwicklung und Durchsetzung klarer Richtlinien und Verfahren. Das geht von der Datenerfassung über die Verantwortlichkeiten bis hin zur Nutzung und Speicherung. (Quelle: IBM )
Datenmanagement sind also die operativen Prozesse, also das WIE zur Datenhaltung. Data Governance schafft den strategischen und organisatorischen Rahmen dazu, also das WARUM bzw. nach welchen Regeln. Die beide Disziplinen ergänzen sich, haben aber unterschiedliche Schwerpunkte.
Backup-Strategien
Backups sind mehr als technische Notwendigkeit. Sie sind integraler Bestandteil einer umfassenden Datenresilienz- und Notfallstrategie. Mit einem durchdachten Backup-Konzept stellst du den Betrieb nach einem Systemausfall schneller wieder her und kannst die Folgen von Ransomware-Angriffen und menschlichen Fehlern eingrenzen, die besonders in vernetzten Produktionsumgebungen schwerwiegend sein können.
Backups sind Teil des Business Continuity Managements, was alleine ganze Bücher füllt. Ich will allerdings einen kurzen Einblick geben. Deswegen folgen drei beispielhafte Aspekte, die du berücksichtigen solltest:

Datendifferenzierung: Verschiedene IIoT-Datenkategorien erfordern unterschiedliche Backup-Ansätze. Während Prozessdaten zur Qualitätssicherung umfassend gesichert werden müssen, benötigen temporäre Sensordaten möglicherweise nur selektive Backups. Die richtige Kategorisierung bildet die Grundlage einer kosteneffizienten Backup-Strategie.
Wiederherstellungsziele: Recovery Point Objective (RPO) und Recovery Time Objectives (RTO) definieren, welchen Datenverlust ein Unternehmen verkraften kann und wie schnell Systeme wieder verfügbar sein müssen. In der Smart Factory könnten Ausfälle direkte Produktionskonsequenzen haben, weshalb diese Ziele aus einer Risikobewertung der Geschäftsprozesse abgeleitet werden sollten.
Backup-Methode: Hier stehen sie vor besonderen Herausforderungen, denn Zeitreihendatenbanken wachsen kontinuierlich und Edge-Speicher sind oft über die gesamte Produktionsinfrastruktur verteilt. Dabei können entweder Inkrementelle oder vollständige Backups erstellt werden. Die Wahl der passenden Methode sollte sich an der Kritikalität der Daten, verfügbaren Infrastruktur und den definierten Recovery-Zielen orientieren. Häufig ist ein hybrides Modell optimal: regelmäßige vollständige Backups kombiniert mit häufigeren inkrementellen Sicherungen.
Lebenszyklus-Management
Die Lebensphasen von Daten in IIoT-Anwendungen gehen von der Erfassung über die aktive Nutzung bis hin zur Archivierung oder Löschung. Mit einem durchdachten Lebenszyklusmanagement ordnest du jeder Phase die passenden Speichertechnologien, Zugriffsrechte und Aufbewahrungsregeln zu.
Mit zunehmendem Alter verlieren Produktionsdaten oft an Aktualität, bleiben aber für Langzeitanalysen wertvoll. Ein intelligentes Konzept verschiebt Daten automatisch vom teuren Hot-Storage in kostengünstigere Cold-Storage-Lösungen, wenn ihre Zugriffsfrequenz abnimmt.
Besonders in regulierten Branchen müssen bestimmte Produktionsdaten über definierte Zeiträume aufbewahrt werden. Das Lebenszyklus-Management muss diese Compliance-Anforderungen berücksichtigen und gleichzeitig eine Balance zwischen Datenzugriff und Kosteneffizienz finden.
Die manuelle Verwaltung des Datenlebenszyklus ist allerdings bei IIoT-Datenmengen nicht praktikabel. Gut definierte, automatisierte Richtlinien für die Datenverlagerung, Archivierung und Löschung sorgen für Effizienz und Konsistenz.
Mission Recap
Die Datenhaltungsebene bildet das kritische Bindeglied zwischen der Datenerfassung und -analyse in Ihrer Smart Factory. Es geht um die Aufbewahrung Ihres „digitalen Goldes“.
Die richtige Kombination aus Speicherorten (Hot-, Warm- und Cold-Storage), Datenbanktypen und Betriebsführungskonzepten entscheidet darüber, ob Ihre Produktionsdaten langfristig Wert generieren oder im digitalen Chaos versinken.
Multi-Tier-Architekturen mit automatisiertem Datenfluss zwischen den Speicherschichten optimieren die Balance zwischen Kosten und Performance. Je nach Anforderungen Ihrer Smart-Factory-Anwendungen kannst du zwischen relationalen Datenbanken, Zeitreihen-Historikern, verschiedenen NoSQL-Varianten oder Edge-Datenbanken wählen.
Besonders wichtig ist die oft vernachlässigte Betriebsführung: Ohne durchdachtes Datenmanagement, robuste Backup-Strategien und systematisches Lebenszyklus-Management bleibt selbst die technisch raffinierteste Datenhaltungslösung hinter ihren Möglichkeiten zurück.
Wie sieht deine Datenstrategie bisher aus und welche Herausforderungen siehst du dabei? Schreibe es gerne in die Kommentare.
Dein Hauke
„Daten sind wirklich die Grundlage für alles, was wir tun.„
Jeff Weiner
Links zu den anderen Artikeln der Serie:
- IIoT-Komplexität beherrschen mit dem Vier-Ebenen-Modell
- Grundlagen der Datenerfassung und -umsetzung in der Smart Factory
- Navigation für Produktionsdaten auf der Datentransferebene
- Erkenntnisse gewinnen auf der Datenauswertungsebene in IIoT-Anwendungen




Schreibe einen Kommentar