
Willkommen zurück zur Space Analysis. Dies ist Teil 2 des Pumpenmonitoring, in dem wir in die Umsetzung gehen.
„Okay, der Business Case steht. 80.500 € Einsparung pro Jahr klingen gut. Aber wie baue ich das jetzt konkret auf? Welche Sensoren? Wie muss das Netzwerk aussehen? Brauche ich Software dafür?“
Vor diesen Fragen stehen viele Menschen, wenn sie an dieser Stelle sind. Der Business Case überzeugt, die Budgetfreigabe ist da und dann kommt die Unsicherheit: Wo fange ich an? Was brauche ich wirklich? Was kostet das konkret? Genau hier setzt Teil 2 dieser Space Analysis an.
Im ersten Teil haben wir den Business Case aufgebaut und zwar 80.500 € Einsparung pro Jahr durch Pumpenmonitoring mit IIoT, sowie die Ziele definiert (50% weniger Ausfälle, 40% Kostensenkung). Außerdem haben wir festgelegt, welche Parameter wir überwachen: Vibration, Lagertemperatur und Förderdruck.
Jetzt wird es konkret, denn in diesem zweiten Teil zeige ich dir die komplette technische Umsetzung. Strukturiert nach meinem Vier-Ebenen-Modell navigieren wir gemeinsam durch.
Bereit für den Deep Dive? Los geht’s! 🚀
Mission Architecture – Das Vier-Ebenen-Modell in Aktion
In vielen IIoT-Projekten kommt es zu Showstoppern: Sensoren werden gekauft, aber die Datenübertragung vergessen. Oder eine Datenbank wird aufgesetzt, aber niemand weiß, wie die Daten ausgewertet werden sollen. Mithilfe meines Vier-Ebenen-Modells können wir unserer IIoT-Anwendung von Sensor bis Dashboard Struktur geben, sodass wir die Pumpenmonitoring Umsetzung systematisch planen.
- Ebene 1 – Datenerfassung: Welche Sensoren setzen wir ein?
- Ebene 2 – Datentransfer: Wie gelangen die Daten ins Netzwerk?
- Ebene 3 – Datenhaltung: Wo speichern wir die Zeitreihen?
- Ebene 4 – Datenauswertung: Wie werten wir aus?
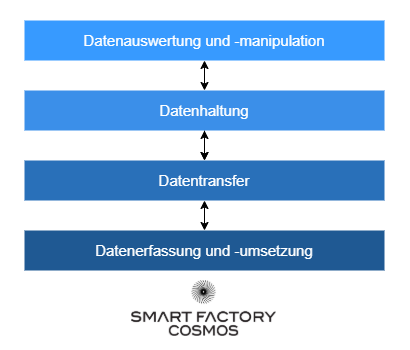
Jede Ebene baut auf der vorherigen auf. Deshalb starten wir ganz unten, bei den Sensoren.
Ebene 1: Datenerfassung
Basierend auf den in Teil 1 definierten Messgrößen (Vibration, Temperatur, Druck) geht es bei der Umsetzung des Pumpenmonitoring in der Datenerfassungsebene darum, diese physikalischen Werte in elektrische Signale bzw. Daten umzuwandeln. Dazu kommen folgende Sensoren zum Einsatz:
- Vibration an Motor und Pumpe: IFM VKV021 Schwingungswächter (ca. 250 € / Sensor) mit IO-Link
- Lagertemperatur: IFM TS2229 PT100-Temperatur-Kabelsensor mit Anlegefühler (ca. 75 € / Sensor) mit IFM TR7439 Auswerteelektronik für Temperatursensoren mit IO-Link (ca. 300 € / Sensor)
- Förderdruck: IFM PN7094 Drucksensor (-1 bis +10 bar) mit IO-Link (ca. 350 € / Sensor)

Alle Sensoren sind IO-Link-fähig, sodass wir neben dem reinen Messwert auch Diagnosedaten (Sensor-Temperatur, Betriebsstunden, Fehlerstatus) und Remote-Parametrierung (Schwellwerte zentral anpassen) erhalten können. Dazu setzen wir einen IFM AL1350 IO-Link Master mit IoT-Schnittstelle ein (ca. 340 €).

Dank der integrierten IoT-Schnittstelle kann der AL1350 Sensor-Daten direkt per MQTT an einen Broker publishen ohne, dass eine SPS dazwischen geschaltet werden muss. Dadurch reduziert sich die Systemkomplexität und eine direkte Anbindung ist möglich. Der IO-Link-Master wird dazu per Ethernet in das Firmennetz eingebunden.
Die Kosten für die genannten Komponenten belaufen sich auf 1.565 €. Außerdem rechne ich für eine fachgerechte Montage noch Kleinteile und Materialien von ca. 400 € je Pumpe dazu, sodass die Gesamtkosten bei 1.965 € je Pumpe bzw. 19.650 € für alle Pumpen liegen.
Ebene 2: Datentransfer
Die Datentransferebene beginnt dort, wo die Sensordaten den IO-Link Master verlassen und ins Netzwerk übertragen werden. Dabei ist das Ziel ist, die Daten sicher, zuverlässig und skalierbar von den 10 Pumpen zu zentralen Auswertungssystemen zu transportieren. Ein entscheidender Schritt in der Pumpenmonitoring Umsetzung. Dazu müssen wir diverse Aspekte betrachten: Netzwerksegmente, Protokolle, Sicherheitskonzept, Bandbreite.
Annahme: Basis-IT-Infrastruktur vorhanden
Ich gehe davon aus, dass eine grundlegende IT-Infrastruktur im Werk existiert: Verkabelung, Switches, Firewall. Falls nicht, müssen diese Kosten zusätzlich eingeplant werden (~5.000-10.000 € für kleine Werke).
Netzwerkarchitektur: IT/OT-Trennung
Die 10 IO-Link Master werden im separaten OT-Netzwerk (Operational Technology, z.B. VLAN 100) betrieben, das vom IT-Firmennetzwerk (z.B. VLAN 10) getrennt ist. Diese Segmentierung ist essentiell für die Sicherheit und verhindert, dass Produktionsanlagen direkt aus dem Büro-Netzwerk oder dem Internet erreichbar sind.
Diese IT/OT-Trennung ist Stand der Technik, da sie oft eine Compliance-Anforderung nach ISO 27001 oder IEC 62443 ist. Selbst bei internen Projekten: Produktionsanlagen sollten niemals direkt im Büro-Netzwerk hängen. Schließlich darf ein Ransomware-Angriff über eine Phishing-Mail im Büro die Produktion nicht lahmlegen.
Protokoll-Stack: Vom Sensor bis zur Anwendung
Die Datenübertragung nutzt verschiedene Protokolle auf unterschiedlichen Ebenen, wobei der AL1350 im Mittelpunkt steht:
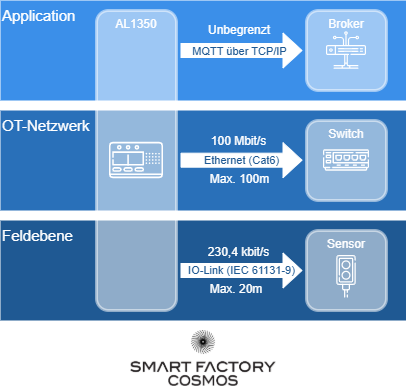
MQTT: Das Rückgrat der IoT-Kommunikation
Der IFM AL1350 ist MQTT-fähig. Dabei handelt es sich um ein leichtgewichtiges Publish/Subscribe-Protokoll, das perfekt für IoT-Kommunikation geeignet ist. Dazu kommt immer ein MQTT-Broker zum Einsatz, was eine Software ist, die im Netzwerk die MQTT-Kommunikation managet.
In MQTT wird die Semantik der Daten in einer Topic-Struktur dargestellt. Wir verwenden eine hierarchische Topic-Struktur nach Best Practices:
werk/pumpen/{pumpen_id}/{parameter}/{messwert} Beispiele:
werk/pumpen/pumpe_01/vibration/motor/rms_value
werk/pumpen/pumpe_01/vibration/motor/status werk/pumpen/pumpe_01/temperatur/lager/value werk/pumpen/pumpe_01/druck/saugleitung/value werk/pumpen/pumpe_10/...Warum diese Struktur?
- Hierarchisch: Einfaches Filtern (z.B. „werk/pumpen/pumpe_01/#“ für alle Daten von Pumpe 1)
- Skalierbar: Neue Pumpen/Parameter ohne Änderung hinzufügbar
- Selbsterklärend: Topic-Name zeigt, was gemessen wird
Der Datenfluss sieht bis hierhin folgendermaßen aus:
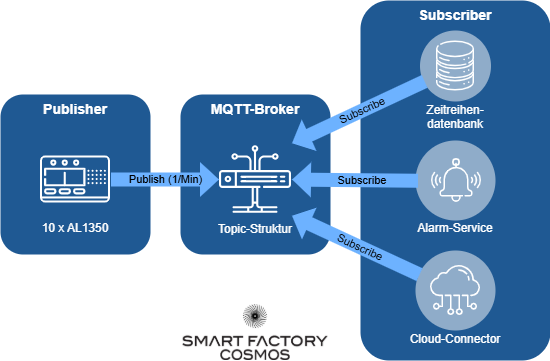
In MQTT wird außerdem der Quality of Service (QoS) Level festgelegt. Wir entscheiden uns für QoS 1 (at least once), was bedeutet, dass die Daten mindestens einmal zugestellt werden, selbst bei kurzen Netzwerk-Ausfällen.
Sicherheitskonzept
Das Sicherheitskonzept für unsere Lösung besteht aus vier Punkten.
- Netzwerk-Segmentierung
- OT-Netzwerk (VLAN 100): Nur Pumpen-Equipment
- IT-Netzwerk (VLAN 10): Firmennetzwerk
- Firewall dazwischen: Nur MQTT-Traffic (Port 8883) erlaubt
- Verschlüsselung
- MQTT über TLS/SSL (Port 8883 statt unverschlüsseltem 1883)
- Zertifikate für AL1350 und Broker
- Verhindert Mitlesen der Sensordaten
- Authentifizierung
- Jeder AL1350 hat eigene MQTT-Credentials (Username/Password)
- Nutzung von Access Control Lists (ACL):
z.B. darf Pumpe 1 nur auf „werk/pumpen/pumpe_01/#“ publishen - Verhindert versehentliches Überschreiben fremder Daten
- Firewall-Regeln
- OT → IT: Nur MQTT (Port 8883) zu Broker-IP erlaubt
- IT → OT: Blockiert (keine Zugriffe von Büro ins OT-Netz)
- Internet → OT: Komplett blockiert
Ebenen 2 – 4 vereint in einem System
Für diese Pumpenmonitoring Umsetzung nutzen wir ThingsBoard Community Edition, wobei es sich sich um eine Open-Source IoT-Plattform handelt, die IoT-Gateway, Datenbank, Visualisierung und Alarme in EINEM System vereint.
Klassischerweise würde man vier Systeme verwenden, und zwar Mosquitto (MQTT-Broker), InfluxDB (Datenbank), Grafana (Dashboards) und Node-RED (Alarme). Das funktioniert hervorragend, bedeutet aber: 4 verschiedene Installationen, 4 verschiedene UIs zu lernen, 4 Systeme zu warten.
ThingsBoard reduziert diese Komplexität, ohne dabei auf Funktionalität zu verzichten. Besonders für Teams, die ihr erstes IIoT-Projekt umsetzen, ist der All-in-One-Ansatz ein Vorteil. Für unser Szenario (10 Pumpen, 40 Sensoren) ist ThingsBoard CE also perfekt geeignet. Die Community Edition ist kostenlos und skaliert problemlos auf bis zu 1.000 Geräte, sodass wir mehr als genug Spielraum für zukünftige Erweiterungen haben.
In dieser Architektur vollendet ThingsBoard Ebene 2 (Datentransfer) und vereint Ebene 3 (Datenhaltung) + Ebene 4 (Dateninterpretation) in einem System. Das vereinfacht die Architektur erheblich!
Abschluss des Datentransfers mit MQTT
Im vorherigen Abschnitt habe ich bereits den Datenfluss aufgezeigt, jedoch noch mit einem beispielhaften MQTT-Broker und Subscribern. Mit ThingsBoard wird dies nun konkret. Damit wir die Daten von den IO-Link Mastern abholen könne, müssen wir das ThingsBoard entsprechend konfigurieren. Dafür haben wir zwei Optionen für die Anbindung:
- Native MQTT API (direkt zum ThingsBoard MQTT Broker)
- IoT Gateway (für komplexe Protokoll-Übersetzungen)
Für unser Setup nutzen wir die einfachste und direkteste Methode, nämlich die Native MQTT API ist.
Anschließend legen wir ein Device in ThingsBoard an (z.B. „Pumpe_01“). Dadurch wird automatisch ein Access Token generiert.
Device: Pumpe_01
Access Token: A1B2C3D4E5F6G7H8I9J0Diesen Access Token nutzen wir im nächsten Schritt, um die IO-Link Master jeweils zu konfigurieren.
MQTT Broker: thingsboard.firma.local
Port: 1883 (unverschlüsselt) oder 8883 (TLS/SSL)
Client ID: Pumpe_01
Username: [Access Token des Devices]
Password: [leer]
Topic: v1/devices/me/telemetryAlle Messwerte werden anschließend als Key-Value-Paare in einem JSON-Objekt gesendet, der sogenannte Payload.
{
"value": 6.2,
"timestamp": 1709308800,
"status": "OK",
"unit": "mm/s"
}ThingsBoard erkennt die Telemetrie automatisch und speichert sie in der Zeitreihen-Datenbank.
Für erweiterte Setups (z.B. mit ThingsBoard IoT Gateway für Protokoll-Übersetzung, Custom Topics, oder Attribut-Updates) siehe die offizielle Dokumentation:
Testen wir die Verbindung, dann sollte im AL1350-Webinterface der Status „MQTT Connected“ erscheinen. In ThingsBoard siehst du schließlich unter „Devices → Pumpe_01 → Latest telemetry“ die eingehenden Daten in Echtzeit.
Ebene 3: Datenhaltung
Zudem haben wir in ThingsBoard auch die Wahl des Datenbanktyps, den wir für die Pumpenmonitoring Umsetzung nutzen wollen. Wir können entweder eine SQL-Datenbank (PostgreSQL) oder eine Kombination aus SQL-Datenbank und eine Zeitreihendatenbank (TimescaleDB) für die dedizierte Zeitreihen-Speicherung. Da wir jedoch in unserem Projekt kein großes Datenvolumen zur Speicherung erwarten (weniger als 5.000 Datenpunkte pro Sekunde), reicht eine PostgreSQL-Datenbank aus.
Näheres zur Auswahl der Speicher findest du in diesem Abschnitt der Dokumentation:
Working with telemetry data
Betrachten wir als nächstes, welchen Storage wir für unsere Daten benötigen, dann müssen wir zunächst festlegen, wie oft wir die Daten an den Pumpen abfragen. Da unser Anwendungsfall nicht im Bereich der Prozessüberwachung liegt und Pumpenausfälle keine Frage von Millisekunden sind, haben wir auch keinen Anspruch an eine Echtzeitfähigkeit. Uns reicht eine Anfragefrequenz von 1/Minute aus, sodass wir mit unseren vier Sensoren pro Pumpe auf:
- 1.440 Messwerte/Tag/Sensor
- ~104 KB/Tag/Pumpe
- ~31 MB/Monat (10 Pumpen)
Das ist ein verschwindend geringes Datenaufkommen, sodass wir für dieses Projekt keine Datenhaltungsstrategie anwenden müssen. Zu dieser Erkenntnis kommt auch dieser Beitrag im ThingsBoard Blog.
Ebene 4: Datenauswertung
Hier geht es darum, aus den Rohdaten Erkenntnisse zu gewinnen, quasi die Schaffung des Mehrwerts der Pumpenmonitoring Umsetzung. ThingsBoard bietet dafür drei zentrale Funktionen: Device Management für die Organisation aller Pumpen, Dashboards für die Visualisierung und die Rule Engine für automatische Alarme.
Organisation aller Pumpen im Device Management
In ThingsBoard wird jede Pumpe als Device angelegt. Das ermöglicht einerseits eine zentrale Verwaltung aller 10 Pumpen mit allen relevanten Informationen und andererseits die Verwendung der Stammdaten der Pumpen in den weiteren Dashboards und Mitteilungen.
Device-Konfiguration (Beispiel Pumpe 1):
{
"name": "Pumpe_01",
"type": "Vakuumpumpe",
"label": "Halle A, Standort 1",
"attributes":
{
"serialNumber": "AL1350-12345",
"installDate": "2026-01-15",
"location": "Halle A",
"manufacturer": "Busch Vacuum",
"model": "R5 RA 0100",
"warrantyUntil": "2029-01-15",
"lastMaintenance": "2025-12-10",
"nextMaintenance": "2026-06-10"
}
} Vorteil: Dadurch sind alle pumpenrelevanten Informationen an einem Ort und nicht verstreut in Excel-Listen, Wartungsplänen oder Inventar-Systemen. Du siehst auf einen Blick:
- Status (Online/Offline)
- Letzte Aktivität
- Aktuelle Messwerte
- Alarme
Näheres zu Devices findest du hier in der Doku von ThingsBoard:
Daten Visualisieren in Dashboards
ThingsBoard bietet einen Drag & Drop Dashboard-Editor mit vorgefertigten Widgets, wovon es ~60 vorgefertigte Optionen gibt:
- Diagramme: Line, Bar, Area, Torten
- Tachometer: Analog, Digital, Radial
- Karten: Standorte im Werksplan (OpenStreetMap, Google Maps)
- Tabellen: Sortierbar, filterbar, exportierbar
- Status-Cards: Aktueller Wert + Grenzwert + Status (grün/gelb/rot)
- Alarme: Alarm-Liste, Alarm-Historie
Praxis-Tipp:
Starte mit einfachen Dashboards (aktuelle Werte und Trend). Erweiterte Visualisierungen (Heatmaps, 3D-Ansichten) können später ergänzt werden.
Wir erstellen zwei Dashboard-Typen:
- Dashboard 1 zeigt den Gesamtstatus aller Pumpen auf einen Blick mit folgenden Widgets
- Status-Karten (grün/gelb/rot) pro Pumpe
- Tabelle mit aktuellen Werten (sortierbar)
- Alarm-Historie (letzte 24h)
- Standort-Karte (Pumpen im Werksplan)
- Auf Dashboard 2 kann man aus allen Pumpen auswählen, für welche man spezifische Details einsehen möchte. Dazu verwenden wir folgende Widgets
- Aktuelle Werte (Gauges oder Karten)
- Zeitreihen-Charts (24h, 7 Tage, 30 Tage)
- Geräte-Informationen (Attributes)
- Alarm-Historie dieser Pumpe
- Wartungsprotokoll
Bei der Gestaltung der Dashboards gibt es unzählige Möglichkeiten der Gestaltung. Da dies nur ein beispielhafter Use Case ist, habe ich derzeit kein tatsächliches Dashboard mit relevanten Daten, welches ich dir zeigen könnte. Nimm‘ dir deswegen an dieser Stelle die Zeit zu schauen, wie das Dashboard für dich am besten aussieht oder schaue dir meinen Buchtipp in diesem Beitrag an. Hier ein Beispiel, wie es aus einem anderen Use Case aussehen kann:
Alarme & Automatisierung mit der Rule Engine
Die Rule Engine ist das Herzstück der Automation in ThingsBoard. Sie arbeitet mit Rule Chains. Dabei handelt es sich um visuellen Workflows, die definieren, was bei bestimmten Ereignissen passiert. Hier ein paar Beispiele, wie solche Alarme aussehen können:
| Trigger | Bedingung | Aktion |
|---|---|---|
| Vibration kritisch | >7 mm/s für 5 Min | Email + SMS + Dash-board-Alarm |
| Temperatur hoch | >70°C für 3 Min | Email + Wartung planen |
| Pumpe offline | Keine Daten >10 Min | SMS an Techniker |
| Druck abnormal | < -0,3 bar | SMS an Techniker |
| Mehrere Alarme | 3+ Alarme in 1h | Email an Schicht-leiter |
Die Rule Chain baut sich für das Beispiel Vibration kritisch folgendermaßen auf:

Die Rule Chain baut sich aus verschiedenen Nodes auf. Folgende Optionen gibt es dazu:
- Filter Nodes: Bedingungen prüfen (>, <, ==)
- Enrichment Nodes: Daten anreichern (z.B. Standort hinzufügen)
- Transformation Nodes: Daten umwandeln (z.B. °F → °C)
- Action Nodes: Aktionen ausführen (Email, SMS, REST API)
- External Nodes: Integration mit Drittsystemen (JIRA, Slack, etc.)
Bei den Action Nodes stehen diverse Kanäle zur Alarmmeldung zur Verfügung. ThingsBoard unterstützt:
- Email (SMTP)
- SMS (Twilio, AWS SNS)
- Push-Notifications (Firebase, Mobile App)
- Slack (Webhook)
- Microsoft Teams (Webhook)
- Telegram (Bot)
- REST API (für Custom Integration)
Hier findest du eine umfangreiche Beschreibung der Rule Engine in ThingsBoard:
Das Vier-Ebenen-Modell für das Pumpen-Monitoring
Mit dem Abschluss der vierten Ebene haben wir alles, was wir für unsere Pumpenmonitoring Umsetzung benötigen. Die komplette Anwendung in der Darstellung des Vier-Ebenen-Modells sieht somit folgendermaßen aus:
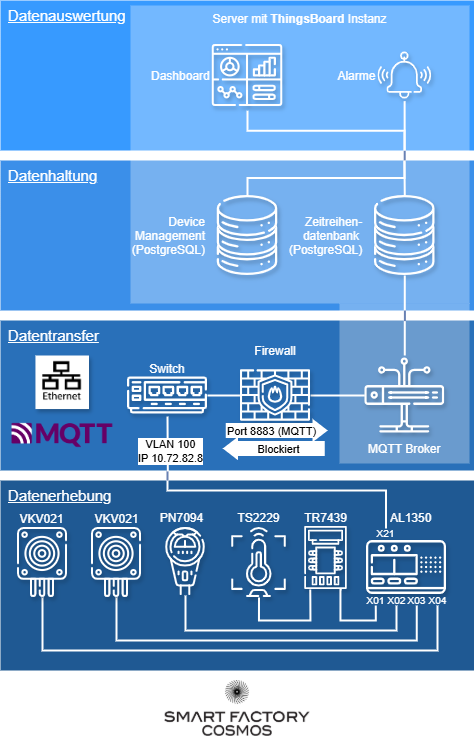
Mission Roadmap – Der Weg zum Erfolg
Dieses Beispiel dient, wie bereits erwähnt, als Blaupause für die Umsetzung einer Lösung. Deswegen ist es an dieser Stelle für mich nicht möglich, dir vorherzusagen, wann und wie sich der Erfolg einstellt. Dafür aber eine realistische Roadmap zur Erreichung der in Teil 1 festgelegten Ziele. Wir teilen sie in 4 Phasen ein:
1. Phase: Inbetriebnahme (Monat 1-2)
- Installation der Sensoren an 10 Pumpen
- ThingsBoard-Konfiguration
- Erste Datenerfassung
- Schwellwerte kalibrieren
2. Phase: Optimierung (Monat 3-6)
- Feintuning der Alarme (Fehlalarme reduzieren)
- Dashboards anpassen basierend auf Nutzerfeedback
- Erste Wartungsmaßnahmen basierend auf Daten
3. Phase: Bewertung (Monat 6-12)
- ROI-Berechnung mit realen Daten
- Vergleich: Ausfälle vorher vs. nachher
- Entscheidung: Ausweitung auf weitere Maschinen?
4. Phase: Skalierung (ab Monat 12)
- Weitere Pumpen ausrüsten
- Predictive Analytics einführen
- Integration mit Wartungssystemen
Präsentiere diese Roadmap bereits bei der Projekt-Vorstellung. So vermeidest du unrealistische Erwartungen, wie z.B. „Warum spart das System noch nichts?“ in Monat 2.
Mission Challenges – Worauf du achten solltest
Wie sagt man so schön: Erstens kommt es anders und zweitens als man denkt. Bei der Umsetzung vom Pumpenmonitoring wirst du sicherlich auf Herausforderungen stoßen, die du meistern musst. Das ist normal, denn deine Arbeitsumgebung befindet sich mit so einem Projekt in einer Lernphase. Deswegen hier ein paar Beispiele von möglichen Stolpersteinen:
- Stakeholder-Erwartungen managen: Management erwartet oft sofortige ROI. Kläre von Anfang an, dass das System 3-6 Monate zum Lernen braucht.
- Fehlalarme in den ersten Wochen: Schwellwerte müssen iterativ angepasst werden. Starte konservativ (höhere Werte), dann schrittweise senken. Bereite die Empfänger vor, um Alarm-Fatigue zu vermeiden
- IT/OT-Zusammenarbeit: IT-Abteilung und Produktion sprechen oft unterschiedliche Sprachen, sodass du frühzeitig beide einbinden, gemeinsame Ziele definieren solltest.
- Datenqualität sicherstellen: Falsch montierte Sensoren liefern falsche Daten. Investiere Zeit in korrekte Installation und Kalibrierung.
Mit der richtigen Erwartungshaltung und iterativer Optimierung kommst du schließlich sicher ans Ziel.
Wichtig: Deine Umgebung ist einzigartig
In deiner spezifischen Umgebung können weitere Aspekte relevant sein (z.B. abhängig von deiner Produktionsumgebung), die ich in diesem Artikel nicht erwähnt habe. Jede Produktionsumgebung bringt eigene Herausforderungen mit sich. Nutze deswegen diese Blaupause als Startpunkt und ergänze deine eigenen Aspekte.
Mission Recap
Wir sind in diesem Artikel die komplette technische Umsetzung eines Pumpenmonitoring-Systems von Sensoren bis Dashboards durchgegangen. Das Vier-Ebenen-Modell hat uns dabei als roter Faden durch die Komplexität geführt.
Ebene 1 – Datenerfassung: Vier Sensoren pro Pumpe (Vibration Motor/Pumpe, Lagertemperatur, Förderdruck). Ein IO-Link-Master je Pumpe als Datensammler.
Ebene 2 – Datentransfer: MQTT als Protokoll, IT/OT-Trennung als Sicherheitskonzept, hierarchische Topic-Struktur für Skalierbarkeit.
Ebene 3 – Datenhaltung: PostgreSQL in ThingsBoard speichert Zeitreihen. Mit ca. 31 MB/Monat (10 Pumpen) bleibt der Speicherbedarf minimal.
Ebene 4 – Datenauswertung: Dashboards für Visualisierung, Rule Engine für automatische Alarme. Hier entsteht der Mehrwert: proaktive Wartung statt reaktiver Reparatur.
Die wichtigste Erkenntnis: ThingsBoard als All-in-One-Plattform vereinfacht die Umsetzung erheblich. Statt vier separate Systeme zu warten, läuft alles in einer Anwendung.
In Teil 1 dieser Space Analysis haben wir den Business Case aufgebaut: 80.500 € Einsparung pro Jahr. Teil 2 hat diese Theorie anschließend in konkrete Hardware und Software übersetzt. Das Ergebnis: eine vollständige Blaupause, die du für dein eigenes Projekt adaptieren kannst.
Dein nächster Schritt: Starte mit einem Pilotprojekt (2-3 Pumpen), sammle Erfahrungen und skaliere dann auf die nächsten Ebenen.
Safe travels im Smart Factory Cosmos! 🚀
Dein Hauke


Schreibe einen Kommentar